
A common problem in search is ordering large result sets. Consider a user searching for “jacket” on an e-commerce platform. How do we order the large number of results to show the most relevant products first? In other words, what kind of jackets is the user looking for? Suit jackets, sport jackets, winter jackets?
Often, we have the context to infer what kind of jacket a user is looking for based on their interactions on the site. For example, if a user has men’s running shoes in their shopping cart, they are likely looking for men’s sports jackets when they search for “jacket”.
At least to a human that seems pretty obvious. Yet, Amazon will return a somewhat random assortment of jackets in this scenario as shown in the screenshot below.
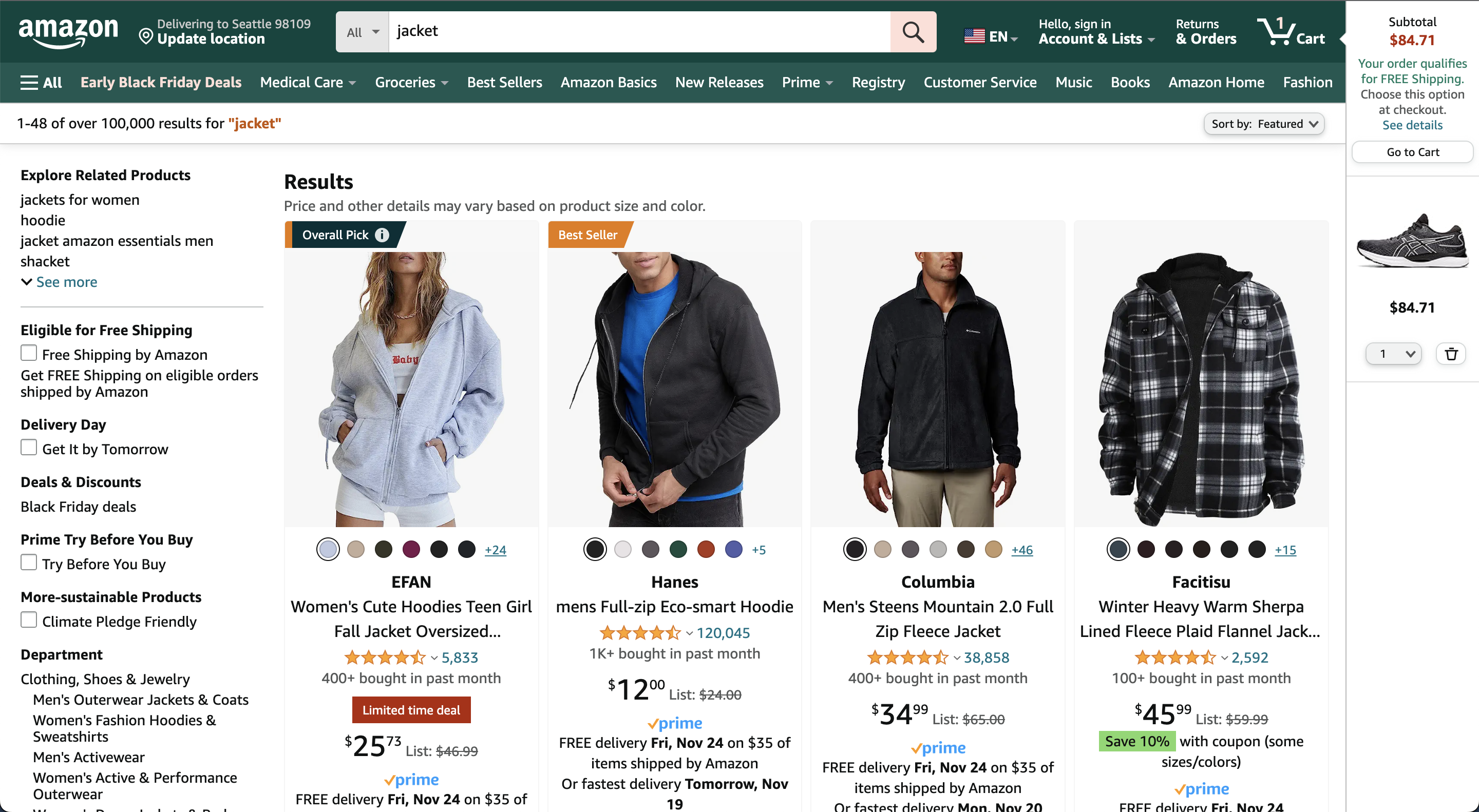
To humans the semantic association between “running shoes” and “sport jackets” is natural, but for machines making such associations has been a challenge. With recent advances in large-language models (LLMs) computers can now compute semantic similarities with high accuracy.
We are going to use LLMs to compute the semantic context of past user interactions via vector embeddings, aggregate them into a semantic profile, and then use the semantic profile to order search results by their semantic similarity to a user’s profile.
In other words, we are going to rank search results by their semantic similarity to the things a user has been browsing. That gives us the context we are missing when the user enters a search query.
In this article, you will learn how to build a personalized shopping search with semantic vector embeddings step-by-step. You can apply the techniques in this article to any kind of search where a user can browse and search a collection of items: event search, knowledge bases, content search, etc.
Step 1: Setup
First, we need to find some realistic product data we can use for our personalized search. We’ll use a recent web scrape of the Flipkart product catalog from Kaggle. Flipkart is India’s largest e-commerce site. We removed incomplete and duplicate records from the dataset.

Second, we need a vector embedding model. A vector embedding model maps a piece of text to a high-dimensional vector that preserves the semantic meaning of the text in the sense that two pieces of text that are similar map to vectors that are close to each other in space.
The embedding model we are using for this tutorial is a quantized version of the all-MiniLM-L6-v2 pre-trained model. This is an off-the-shelf model for sentence embedding trained on a large corpus. The model is small and fast while delivering good performance. “Quantized” means that the model has been transformed to run efficiently on CPUs.
Download this zip archive for the data and vector model you need to follow the steps in this tutorial. It also contains all the code we’ll be writing.
Step 2: API & Architecture
We are going to implement the personalized search as a microservice that exposes a GraphQL API. The API has one query endpoint for the personalized search and one mutation endpoint to record the products a user has browsed. The GraphQL schema for our API is shown below:
type Query {
ProductSearch(query: String!, userid: String!): [Products!]
}
type Products {
id: String!
title: String!
description: String!
brand: String!
average_rating: Float!
sub_category: String!
}
type Mutation {
ProductView(view: ProductViewInput!): ProductViewed
}
input ProductViewInput {
productid: String!
userid: String!
}
type ProductViewed {
_source_time: String!
userid: String!
}
We use PostgreSQL to implement the search and store the semantic user profiles. PostgreSQL is a relational database that supports efficient full-text search and vector data types.
We use Apache Kafka to capture users' product views so that we can process them asynchronously to compute the aggregated semantic user profiles. Kafka is a stream platform to efficiently store and process data streams.
We use Apache Flink to ingest the product data, compute vector embeddings, and compute the semantic user profiles. Flink is a stream processor that reliably processes data from streams with exactly-once guarantees.
We use these 3 data systems for a reliable, flexible, and scalable architecture. PostgreSQL manages data at rest, Kafka manages data in motion, and Flink processes the data. The architecture diagram shows how the data moves through those systems.

- The
ProductViewmutation endpoint gets invoked when a user views a product on the website. - The event gets recorded in Kafka
- Flink processes the
ProductViewevents and aggregates them into semantic user profiles (more on that below). - Flink also ingests product data from the external product catalog, so we have up-to-date product information to search.
- Flink writes the semantic user profiles and product information to PostgreSQL.
- The
ProductSearchquery endpoint gets invoked when a user searches, which is translated to an SQL query against PostgreSQL, and the results are returned to the user.
We could have implemented the entire search microservice with just PostgreSQL and a server. That’s a simpler architecture but has several downsides:
- We have to implement a lot of data processing and failure handling logic in the server to make it work reliably under load.
- Computing vector embedding and aggregating them synchronously can lead to long latencies.
- A spike in traffic to our shopping site would result in a high server load and lots of inserts to PostgreSQL which would degrade search performance.
Using an event-driven architecture as shown above allows us to process the product views and product updates asynchronously, which results in a more robust, reliable, and performant system.
Step 3: Implementation
The big downside of our event-driven architecture is that it’s a lot of work to implement all of those components and make them work efficiently together. Luckily, there is a tool that makes this a lot easier: DataSQRL.
DataSQRL is an open-source compiler for event-driven microservices. With DataSQRL we only have to implement the processing logic of our search microservice and DataSQRL compiles the entire event-driven architecture for us.
Here is how that works. We implement our personalized search engine in a file called aisearch.sqrl using SQL. DataSQRL uses an SQL dialect that adds some syntax and features for stream processing. Let’s look at each of the four parts of the script in more detail.
-- ### PART 1: Imports
IMPORT externaldata.Products; -- Import product information from the catalog
IMPORT searchapi.ProductView; -- Ingest ProductView events from the API
-- Import some functions we are going to need for data processing
IMPORT vector.*;
IMPORT string.concat;
IMPORT text.textsearch;
-- ### PART 2: Process product data
-- Compute a semantic vector embedding for each product
Products.semantics := onnxEmbed(concat(title, '\n', description), '/build/embedding/model_quantized.onnx');
-- Convert the stream of product updates to a state table with the most recent product information
Products := DISTINCT Products ON id ORDER BY _ingest_time DESC;
-- ### PART 3: Compute semantic profiles from product views
-- Join in the semantic vector embedding for the product a user viewed
ProductViewVector := SELECT v.userid, p.semantics, v._source_time
FROM ProductView v TEMPORAL JOIN Products p ON v.productid = p.id;
-- Aggregate all those vector embeddings into a semantic profile for each user
UserProfile := SELECT userid, center(semantics) as semanticContext FROM ProductViewVector GROUP BY userid;
-- ### PART 4: Personalized Search
-- Retrieve the products that match the query and order them by semantic similarity to the user's profile
ProductSearch(@query: String, @userid: String) := SELECT p.* FROM
(SELECT * FROM Products WHERE textsearch(@query, title) > 0) p
LEFT JOIN (SELECT * FROM UserProfile WHERE userid = @userid) u
ORDER BY coalesce(cosineSimilarity(p.semantics, u.semanticContext),0.0) DESC;
Let’s go over the 4 parts of the implementation:
- We import the product data from an external data system. For this tutorial, the product data is imported from a file (included in the archive), but DataSQRL supports multiple data sources. We also import
ProductViewevents from the API that are created when a user invokes the corresponding mutation endpoint. Lastly, we import a few functions that we’ll use in our script. - We preprocess the
Productsdata by computing a vector embedding for the title and description of each product using the LLM. Since we are importing a stream of product data, because products may change over time, we deduplicate the stream to get the most recent version for each product. - We join the
ProductViewevents against theProductsstate table to look up the vector embedding for the product a user viewed. We use a temporal join so that we look up the associated vector at the time of the event. Then we aggregate all theProductViewVectorsbyuseridto create the semanticUserProfileas the centroid of all product vectors the user has visited. - To answer a search query, we retrieve the matching products and the vector that represents the semantic profile of a user. We order the results by their semantic similarity to the semantic user profile by computing the cosine similarity between the respective vectors.
Step 4: Running Our Personalized Search
That’s all we have to implement. Let’s run our personalized search and see how it works in practice.
First, we compile the SQRL script to a microservice with the command:
docker run --rm -v $PWD:/build datasqrl/cmd compile aisearch.sqrl searchapi.graphqls --mnt $PWD
Make sure you run the command in the folder where you unzipped the archive containing the data.
Second, we run the compiled microservice with docker:
(cd build/deploy; docker compose up)
You can access the API in your browser through GraphiQL, which is an IDE for GraphQL APIs, by opening http://localhost:8888/graphiql/.
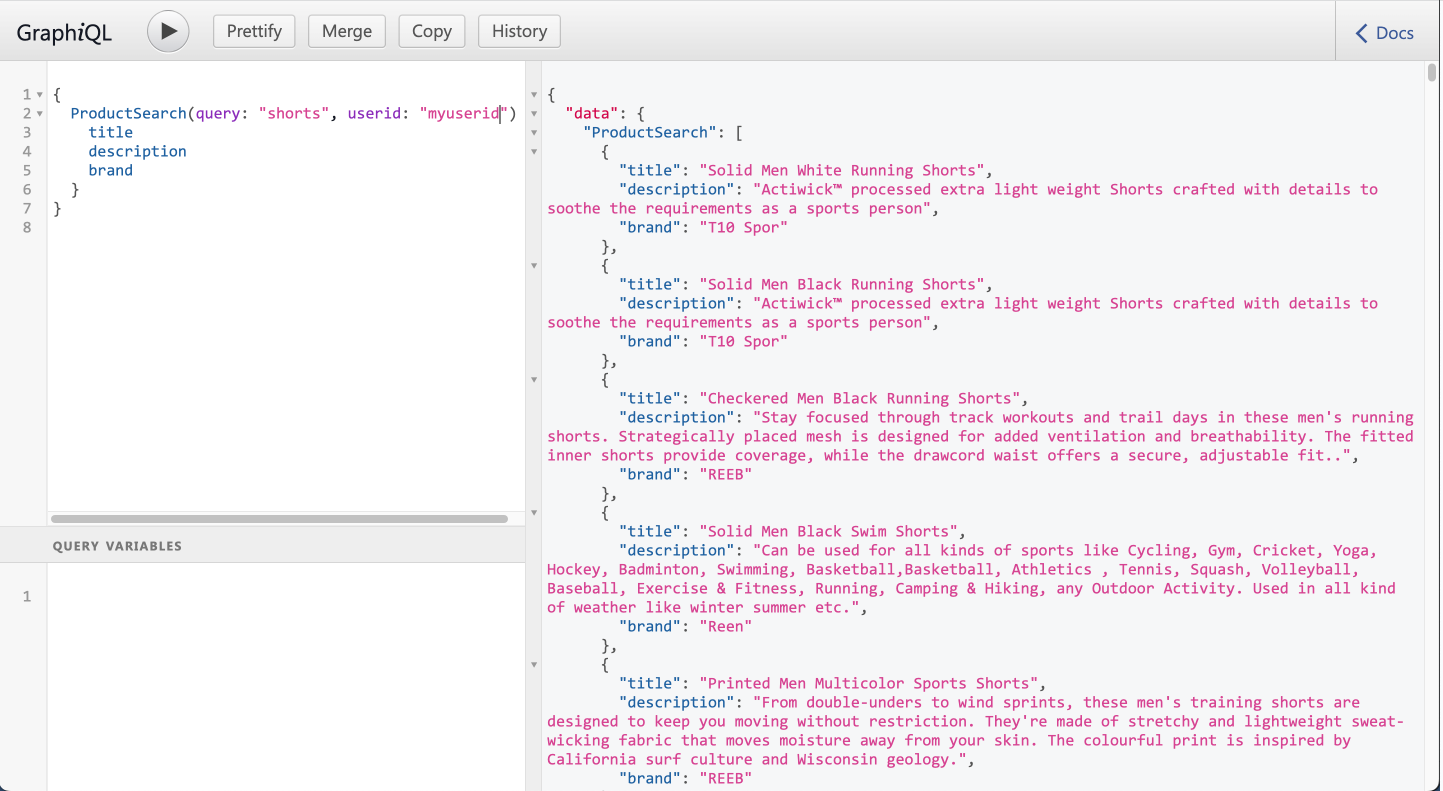
Copy-paste the following GraphQL query into the left-hand side and hit the run button to execute the search query for “jackets”. You’ll get a list of jackets that are offered on Flipkart.
{
ProductSearch(query: "jacket", userid: "myuserid") {
title
description
brand
}
}
The search results are not personalized because we don’t have any context for the user “myuserid” yet. Let’s add some context by having our user visit a product page for running shoes. We do that by running the following mutation query with a payload:
mutation AddView($view: ProductViewInput!) {
ProductView(view: $view) {
_source_time
}
}
Mutations require a payload that specifies which product a user visited. Enter the following JSON payload under "Query Variables" in the bottom left of GraphiQL before running the query:
{
"view":
{
"productid": "f40b93aa-c3b2-5cf4-97c0-92151279464f",
"userid": "myuserid"
}
}
Now, if you run the same search query for “jackets” again with the “myuserid” (click on the history tab to go back to the first query), you should see that the results are tailored to the semantic context of our user. Or try searching for "shorts" for the same user, and you'll get athletic and running shorts.
Step 5: Next Steps
And that’s how you build a personalized search with vector embeddings. Our implementation is only a few lines of code, because DataSQRL generated all the data plumbing for our microservice.
We hope you can use this tutorial as a starting point to implement your own personalized search with LLMs. With DataSQRL, you can add additional sources of data, implement custom scoring functions, and fine-tune the search to your particular use case. For extra credit, you could change the aggregation function to prioritize recent product views or fine-tune the LLM for sentence embedding to our dataset. We’ll discuss those improvements in a future tutorial.
Check out the DataSQRL documentation for more information and star DataSQRL on Github to bookmark the open-source project. Good luck building your AI search and reach out to the community if you have any questions.