
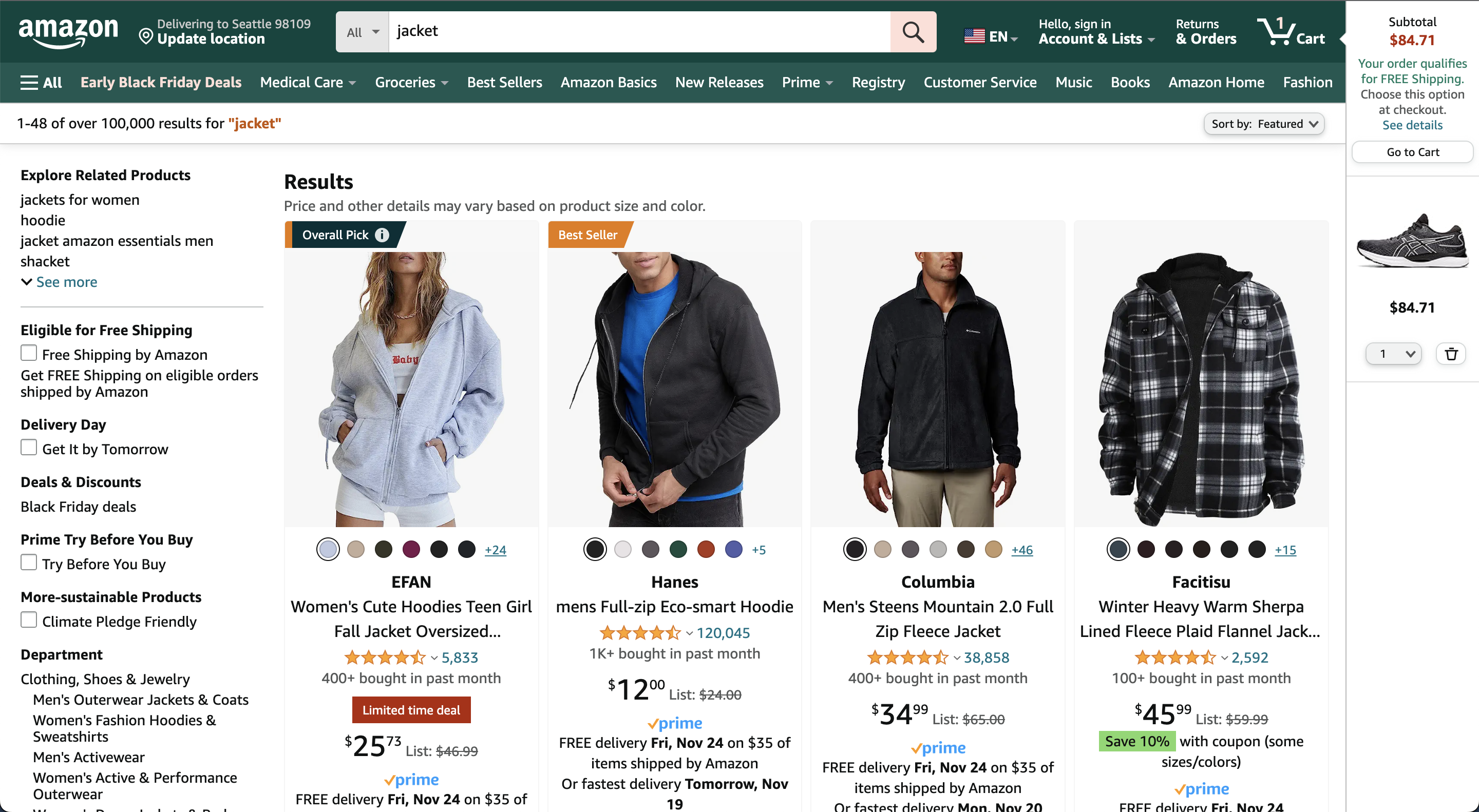
A common problem in search is ordering large result sets. Consider a user searching for “jacket” on an e-commerce platform. How do we order the large number of results to show the most relevant products first? In other words, what kind of jackets is the user looking for? Suit jackets, sport jackets, winter jackets?
Often, we have the context to infer what kind of jacket a user is looking for based on their interactions on the site. For example, if a user has men’s running shoes in their shopping cart, they are likely looking for men’s sports jackets when they search for “jacket”.
At least to a human that seems pretty obvious. Yet, Amazon will return a somewhat random assortment of jackets in this scenario as shown in the screenshot below.
To humans the semantic association between “running shoes” and “sport jackets” is natural, but for machines making such associations has been a challenge. With recent advances in large-language models (LLMs) computers can now compute semantic similarities with high accuracy.
We are going to use LLMs to compute the semantic context of past user interactions via vector embeddings, aggregate them into a semantic profile, and then use the semantic profile to order search results by their semantic similarity to a user’s profile.
In other words, we are going to rank search results by their semantic similarity to the things a user has been browsing. That gives us the context we are missing when the user enters a search query.
In this article, you will learn how to build a personalized shopping search with semantic vector embeddings step-by-step. You can apply the techniques in this article to any kind of search where a user can browse and search a collection of items: event search, knowledge bases, content search, etc.





